Machine Learning Data Pipeline
End-to-end automated data pipeline for scalable machine learning workflows
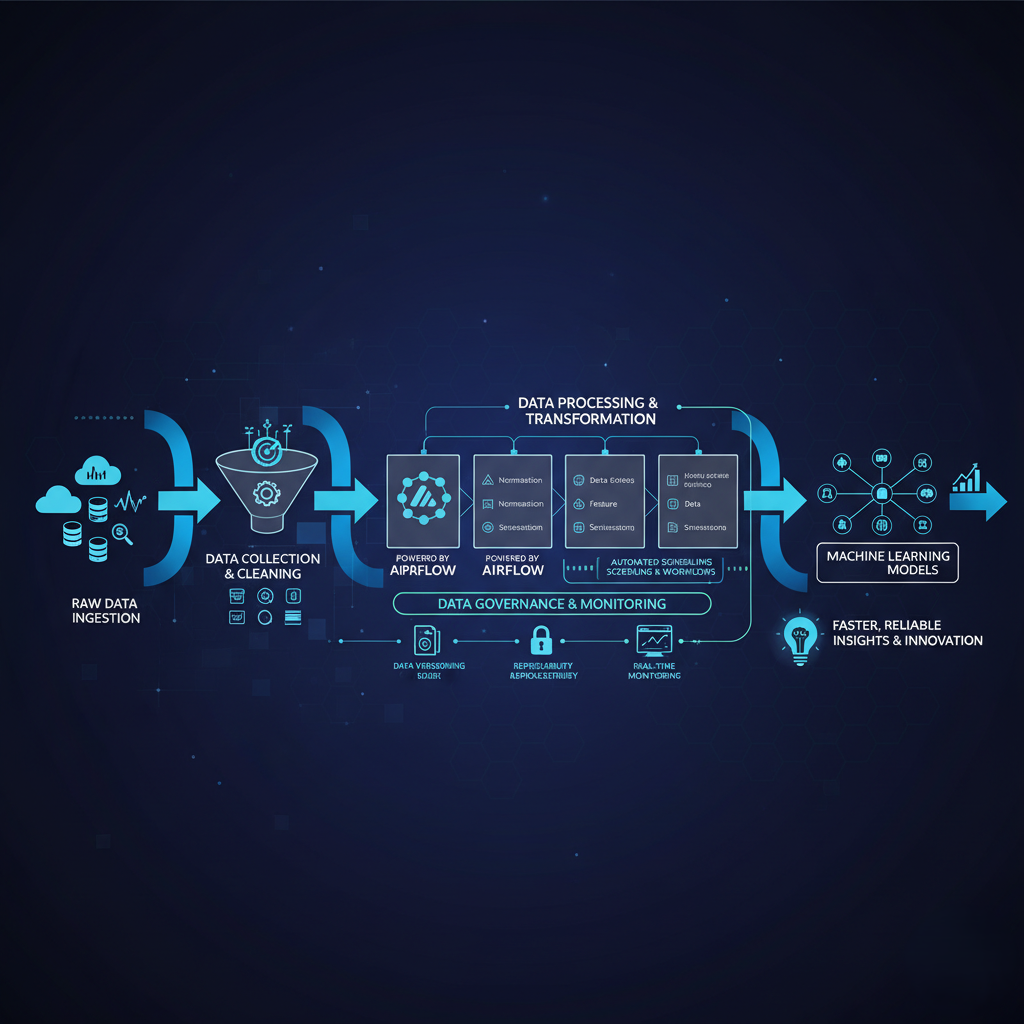
The Problem
Traditional machine learning workflows often involve manual data collection, cleaning, and processing, which are error-prone, time-consuming, and difficult to scale. The Machine Learning Data Pipeline addresses this by automating the entire process — ensuring that high-quality, preprocessed data flows seamlessly into machine learning models.
By standardizing data ingestion and transformation, it reduces inconsistencies and eliminates human error. The integration with Airflow provides automation and scheduling capabilities, allowing teams to handle continuous data streams without manual intervention. Additionally, the pipeline supports data versioning, reproducibility, and monitoring, helping organizations comply with data governance and model auditing standards.
The result is a faster, more reliable, and more scalable ML lifecycle, empowering teams to focus on innovation and insights instead of repetitive data management tasks.
The Solution
The Machine Learning Data Pipeline project is a comprehensive, end-to-end solution designed to automate the flow of data across the entire machine learning lifecycle — from raw data ingestion to model deployment. Built with Python, pandas, scikit-learn, and Apache Airflow, this pipeline ensures clean, consistent, and production-ready datasets for accurate and reliable machine learning model training.
The system is engineered to handle large-scale, multi-source datasets efficiently, automating every stage including data extraction, transformation, loading (ETL), feature engineering, model training, evaluation, and deployment. It integrates seamlessly with cloud platforms such as AWS, GCP, or Azure, providing scalability and continuous workflow management.
The Data Pipeline architecture focuses on modularity and reusability — allowing data scientists and engineers to plug in new data sources, models, and preprocessing modules effortlessly. Built with Airflow DAGs, the workflow is fully orchestrated, version-controlled, and supports scheduled runs for real-time or batch data processing.
With integrated data validation using frameworks like Great Expectations, and support for experiment tracking via MLflow, this system offers a fully managed ML operations (MLOps) environment. It reduces manual overhead, improves reproducibility, and accelerates deployment cycles — ensuring data integrity and consistent model performance across environments.
Key Features:
-
Automated ETL pipeline for structured and unstructured data
-
Scalable data preprocessing and feature engineering
-
Workflow orchestration with Apache Airflow DAGs
-
Integrated ML model training and deployment pipeline
-
Data validation and error handling for quality assurance
-
Version control, logging, and monitoring for transparency
-
Cloud integration for scalable and distributed processing
Ideal for:
-
Data scientists automating model training and data preparation
-
Machine learning engineers managing end-to-end MLOps workflows
-
Organizations processing large, heterogeneous datasets
-
Research and analytics teams improving data reliability and efficiency
This project provides a strong foundation for AI-driven automation, promoting consistency, scalability, and transparency in ML workflows. It’s an excellent example of how machine learning engineering and data pipeline design converge to enable intelligent, production-grade systems.