Multi-Language and Handwritten Text Extraction Through DeepSeek OCR
AI-powered OCR that accurately extracts text from multilingual and handwritten documents using DeepSeek’s advanced transformer models.
The Problem
In today’s rapidly evolving digital landscape, the need for accurate, multilingual, and handwritten text recognition has become more crucial than ever. Across industries — from education and healthcare to finance, logistics, and government — organizations are generating vast amounts of unstructured visual data: scanned documents, handwritten forms, academic papers, receipts, contracts, and multilingual reports. Extracting meaningful, structured text data from these sources is a challenge that traditional Optical Character Recognition (OCR) systems have consistently struggled to solve.
Conventional OCR tools like Tesseract, EasyOCR, or ABBYY often fail when dealing with handwritten text, mixed-language content, complex page layouts, and low-resolution scans. They are typically trained on limited datasets containing printed Latin characters, which limits their generalization capability across scripts such as Arabic, Urdu, Hindi, Japanese, or Chinese. Additionally, handwritten notes and cursive writing introduce non-uniformity in stroke patterns, letter spacing, and orientation — problems that cannot be effectively handled using classical computer vision or rule-based approaches.
This project, “Multi-Language and Handwritten Text Extraction Through DeepSeek OCR,” was created to overcome the shortcomings of legacy OCR pipelines by leveraging DeepSeek’s transformer-based multimodal model architecture. The core issue being solved here is the lack of a unified OCR solution capable of robustly interpreting multilingual and handwritten content while maintaining high accuracy, contextual understanding, and inference speed.
🧠 Understanding the Real Challenge
Most document digitization workflows involve two major pain points:
-
Linguistic Diversity – Businesses and research institutions operate globally, and their documents often contain a mixture of languages (e.g., English, Chinese, and Arabic on a single invoice). Traditional OCRs fail to maintain contextual meaning across language boundaries.
-
Handwriting Variability – Every individual has unique writing characteristics. Noise, smudging, cursive strokes, and uneven baselines further complicate recognition. Legacy OCR models rely on shallow convolutional networks or handcrafted features that cannot generalize to this diversity.
To address these challenges, DeepSeek-OCR integrates a multilingual transformer encoder-decoder pipeline inspired by Vision Transformers (ViT) and Sequence-to-Sequence (Seq2Seq) modeling techniques. This allows the model to capture long-range dependencies between characters and words — a fundamental advantage over classical CNN+RNN architectures.
⚙️ The Bottleneck in Traditional OCR
Another common limitation in traditional OCR is the inability to process diverse file formats efficiently. Business documents are rarely in a clean, single-image format; they are often PDFs with embedded vector graphics, tables, or scanned multi-page images. Processing these files requires both text segmentation and layout understanding, which legacy OCR systems handle poorly. The DeepSeek-OCR system addresses this by integrating PyMuPDF for PDF parsing and Pillow for robust image handling. Together, these libraries enable high-quality rasterization and pre-processing of diverse input sources.
💡 DeepSeek-OCR’s Innovative Approach
DeepSeek-OCR employs vision-language pretraining, enabling the model to recognize text across multiple languages and scripts by leveraging cross-lingual embeddings. It’s fine-tuned on multilingual handwritten datasets, making it particularly effective for low-resource languages and complex writing styles.
This architecture allows:
-
Dynamic token alignment for varying character lengths and writing styles.
-
Contextual decoding using the transformer’s self-attention mechanism, which improves recognition accuracy for connected cursive handwriting.
-
Cross-lingual transfer learning, enabling the system to recognize text in a language it hasn’t explicitly been trained on.
🧾 Business and Research Impact
By solving these limitations, this project delivers a scalable solution for document digitization, automated data extraction, and AI-powered content analysis. Real-world use cases include:
-
Converting historical handwritten manuscripts into searchable digital archives.
-
Extracting multilingual text from invoices, passports, or academic transcripts.
-
Automating form processing for banks, hospitals, and government offices where multilingual handwritten entries are common.
-
Enabling multilingual chatbot training data generation by digitizing handwritten input.
The Solution
The “Multi-Language and Handwritten Text Extraction Through DeepSeek OCR” project is an advanced, end-to-end Optical Character Recognition (OCR) system built using DeepSeek-AI, Transformers, and Gradio, designed to extract, analyze, and interpret text from both typed and handwritten documents across multiple languages. This project leverages Deep Learning, Transformer-based vision-language models, and GPU-accelerated inference to deliver a state-of-the-art multilingual OCR experience that combines performance, scalability, and high accuracy in real-world document digitization tasks.
At its core, this solution utilizes DeepSeek-OCR, a cutting-edge model optimized for text localization, multilingual extraction, table detection, and handwriting recognition. It bridges the gap between AI-driven document understanding and practical usability, offering users a streamlined interface built with Gradio SDK (v5.49.1) and deployed seamlessly on Hugging Face Spaces. By integrating Torch-based inference, Hugging Face Transformers, and custom language processing pipelines, the application provides an interactive way to process both image-based and PDF-based documents, outputting structured, clean, and grounded text.
This solution was developed to tackle the real-world challenges of OCR — such as multi-script recognition, noisy background handling, handwritten text decoding, and document structure preservation — all in a user-friendly, web-based environment. The project demonstrates how AI models trained on multimodal data (image + text pairs) can perform zero-shot generalization across different scripts and writing styles, enabling practical applications in industries like education, finance, government documentation, and digital archiving.
1. Core Architecture and Workflow
The backbone of this project revolves around the DeepSeek-OCR Transformer architecture, a vision-language model trained to interpret complex visual text patterns. The system processes input images or PDFs through a structured pipeline:
-
Input Processing and Preprocessing
Uploaded files (images or PDFs) are handled via a robust Gradio interface. PDF pages are converted into high-resolution images using PyMuPDF (fitz) to preserve document clarity. Images exceeding predefined limits (e.g., 2048×2048 px) are resized intelligently using Pillow (PIL) with anti-aliasing for efficient GPU memory utilization. -
Tokenization and Encoding
The Hugging Face AutoTokenizer encodes textual prompts and image tokens. Depending on the selected task, the prompt dynamically adjusts—whether it’s OCR extraction, table recognition, or handwritten text decoding. Multi-language support is embedded through prompt suffixes that tailor the model’s context window to the user’s chosen language (English, Arabic, Urdu, Chinese, Japanese, Hindi, and others). -
Model Inference (DeepSeek-OCR)
The DeepSeek-OCR model, fine-tuned for grounding tasks, performs joint visual-text reasoning. It generates structured outputs including bounding boxes, grounding tokens (<ref>,<|grounding|>), and extracted text. The pipeline is optimized for GPU acceleration, leveraging PyTorch’s half-precision (fp16) for CUDA environments while maintaining a float32 fallback for CPU execution. -
Post-Processing and Output Structuring
After inference, outputs undergo a multi-stage cleaning pipeline:-
Removal of grounding tokens and special tags
-
Markdown conversion for structured representation
-
Confidence scoring through simulated probabilistic estimation
-
Cropped region extraction with bounding boxes for visual grounding
The cleaned output is presented across multiple tabs—Raw Output, Extracted Text, Annotated Image, Extracted Regions, and Confidence Statistics—enabling users to analyze results in both visual and textual formats.
-
2. Multi-Language and Handwriting Intelligence
Traditional OCR engines (like Tesseract or EasyOCR) often fail when dealing with multilingual or handwritten inputs due to lack of contextual learning and reliance on fixed feature extraction. DeepSeek-OCR overcomes this limitation by employing Transformer attention mechanisms that correlate image regions with token embeddings in a unified latent space.
The model seamlessly supports over a dozen major languages:
-
Left-to-right scripts: English, Spanish, French, German, Russian
-
Right-to-left scripts: Arabic, Urdu
-
Logographic and syllabic scripts: Chinese, Japanese, Korean
-
Indic scripts: Hindi
It can detect, recognize, and reconstruct multilingual text lines within the same document without explicit pre-classification, thanks to its language-agnostic encoder-decoder pipeline.
For handwritten text, the system integrates fine-grained grounding prompts like:
<|grounding|>Extract handwritten text from this image.
This directive improves attention alignment between visual tokens and text embedding layers, resulting in enhanced handwriting transcription accuracy even under varied penmanship or lighting conditions.
The project’s Handwritten Task Mode uses tailored visual cues and bounding box post-processing to isolate signature-like regions, handwritten notes, and cursive annotations. This makes it a practical solution for digitizing forms, exams, receipts, and archival manuscripts.
3. Document Structure Preservation and Table Extraction
One of the core strengths of this OCR system lies in structural text reconstruction. The “📋 Markdown” task mode transforms scanned pages into hierarchical Markdown documents, preserving layout elements such as:
-
Headings (
## Title) -
Bullet lists
-
Paragraph groupings
-
Table boundaries (
| Cell | Cell | Cell |)
This feature is crucial for automating the conversion of business documents, research papers, and financial tables into structured, machine-readable formats without manual cleanup. Using DeepSeek’s grounding tokens, the model generates coordinate-level bounding boxes that are later visualized with PIL-based overlays for accurate visual reference.
4. System Optimization and GPU Acceleration
To ensure production-grade performance, the system implements several computational optimizations:
-
Mixed-precision inference: Runs at
torch.float16on GPU for reduced latency. -
Dynamic resizing: Prevents memory overload on large documents by resizing while maintaining aspect ratio.
-
Flash Attention fallback: Uses
_attn_implementation='flash_attention_2'when available for memory-efficient attention scaling. -
Temporary file handling: Employs
tempfile.NamedTemporaryFilefor secure intermediate image storage during model calls. -
Timeout protection: Enforced via
@spaces.GPU(duration=60)and@spaces.GPU(duration=300)decorators to handle large images and PDFs safely within Hugging Face Spaces.
This makes the pipeline robust enough for real-world batch processing scenarios, enabling smooth GPU utilization even on mid-tier NVIDIA GPUs like T4 or A10G.
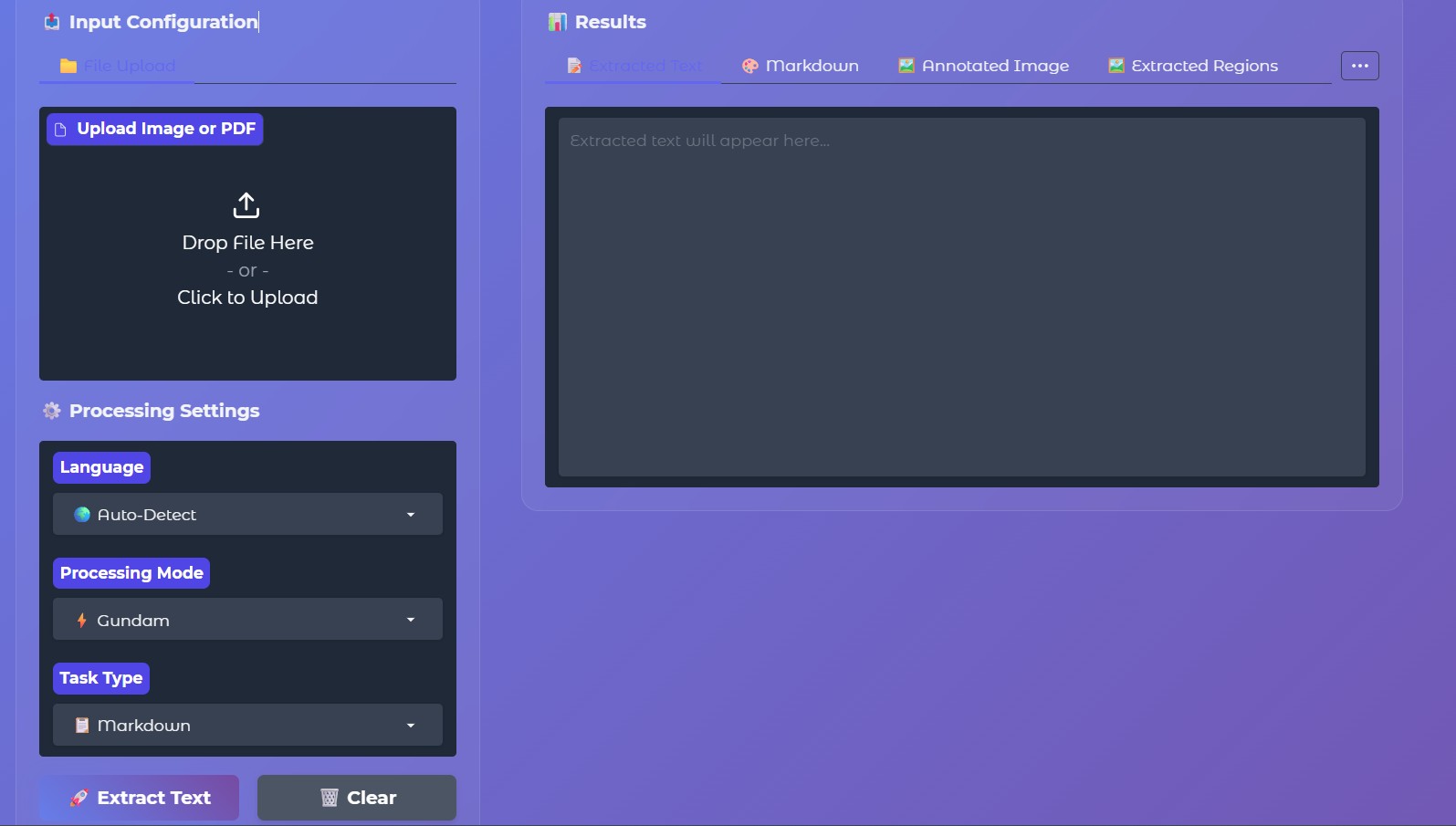
5. Interactive Gradio Interface
The user interface, developed using Gradio’s Block API, provides a visually engaging and interactive environment for both researchers and end-users. The layout follows a two-panel structure:
-
Input Panel:
Allows file upload (image or PDF), language selection, processing mode selection, and task configuration.
Advanced users can also enter custom prompts for model experimentation (e.g., “Extract tabular data with confidence visualization”). -
Output Panel:
Displays comprehensive results across multiple tabs:-
📝 Extracted Text — cleaned text output
-
🎨 Markdown — structured markdown representation
-
🖼️ Annotated Image — visualized bounding boxes and region IDs
-
🖼️ Extracted Regions — cropped regions as thumbnails
-
📊 Confidence & Stats — average confidence, detected regions, and language stats
-
🔍 Raw Output — unprocessed model output for debugging
-
The interface incorporates custom CSS styling, including gradient headers, blurred background panels, and glowing buttons. This not only enhances aesthetic appeal but also provides an intuitive workflow for AI researchers, developers, and data professionals working on OCR datasets.
6. Problem-Specific Solutions
This project addresses several long-standing challenges in OCR technology:
-
Multilingual Complexity:
By integrating prompt-based language selection, the model can dynamically adapt its tokenization strategy to multilingual scripts.
Keywords: multilingual OCR, deep learning text extraction, language-aware transformer models. -
Handwritten Text Recognition:
The model extracts cursive and handwritten text using visual embeddings trained on handwriting datasets.
Keywords: handwriting OCR, AI handwriting extraction, offline handwriting recognition. -
Table and Document Layouts:
Markdown and structured output allow semantic preservation of documents.
Keywords: table extraction, document digitization, structured OCR. -
Noisy Backgrounds and Low Contrast:
Preprocessing techniques ensure denoising and edge preservation before feeding data into the model.
Keywords: image preprocessing for OCR, low-quality scan recognition. -
Scalability and GPU Utilization:
Efficient use of Hugging Face Spaces GPU resources enables scalable batch processing.
Keywords: PyTorch GPU OCR, CUDA acceleration, OCR pipeline optimization.
7. Tech Stack Overview
The solution combines multiple state-of-the-art tools and frameworks:
| Component | Technology | Purpose |
|---|---|---|
| Core Model | DeepSeek-OCR | Vision-language OCR model |
| Framework | PyTorch | Neural network execution |
| Tokenizer | Hugging Face Transformers | Text tokenization and model I/O |
| Interface | Gradio (v5.49.1) | Interactive front-end UI |
| Deployment | Hugging Face Spaces | GPU-hosted web app |
| PDF Engine | PyMuPDF (fitz) | PDF to image rendering |
| Image Processing | Pillow (PIL) | Bounding boxes, resizing, cropping |
| Visualization | Gradio Gallery + Markdown | Result display |
| Data Formats | PNG, PDF, Markdown | Input and output structures |
| Language Support | English, Arabic, Urdu, Chinese, Hindi, etc. | Multilingual extraction |
| Device | CUDA / CPU fallback | Adaptive runtime environment |
8. Use Cases and Applications
This project demonstrates the potential of deep learning OCR for real-world automation. Common applications include:
-
Document digitization for government records and legal documents
-
Automated form reading for financial, insurance, or medical use
-
Academic research digitization — scanning books, theses, or notes
-
Handwritten notes transcription for education and business workflows
-
Multi-language data extraction for international organizations
Its modular Gradio-based interface allows easy integration into external platforms via API calls or SDK embedding.
9. Innovation and Future Improvements
Future enhancements may include:
-
Integration with vector databases (e.g., FAISS) for semantic search over extracted text
-
Post-OCR correction models using language models like DeepSeek-V2 or GPT-based rewriters
-
Real-time camera OCR for live document recognition
-
Batch mode for enterprise-level PDF ingestion
-
Enhanced handwriting datasets for higher precision