Introduction
In today’s AI-driven landscape, the need for machines to understand meaning rather than just match text literally has given rise to vector databases — specialized systems designed to store and retrieve semantic representations of data.
Whether you are building Retrieval-Augmented Generation (RAG) chatbots, recommendation engines, or AI agents, vector databases enable context-aware search and reasoning — something traditional SQL or NoSQL systems simply can’t achieve.
At the heart of this technology lies one fundamental idea: semantic understanding — the ability to capture meaning rather than exact wording. To achieve this, data such as text, images, or audio is converted into vector embeddings, which are numerical representations of meaning.
If you’re developing AI systems or learning how to architect knowledge-based chatbots, understanding how vector databases and embeddings work is absolutely essential.
1. What is Semantic Meaning?
Before understanding vector databases, it’s crucial to grasp the concept of semantic meaning.
In linguistics and AI, semantics refers to the meaning or interpretation of words, phrases, and sentences — beyond their literal text.
For example:
-
The phrases “AI improves productivity” and “Artificial Intelligence enhances efficiency” look different textually, but they express the same semantic idea.
Humans intuitively understand that these two sentences mean the same thing. However, traditional databases (which rely on exact string matching) cannot make that connection — they treat the words “improves” and “enhances” as unrelated.
This is where AI embeddings and vector databases come in.
By representing each sentence as a vector in a high-dimensional space, models trained on vast text corpora can map semantically similar sentences close together. In this space:
-
“AI improves productivity” might map to vector
[0.12, 0.77, 0.43, …] -
“Artificial Intelligence enhances efficiency” maps to
[0.11, 0.74, 0.45, …]
Their cosine similarity (a mathematical measure of angle closeness) will be near 1.0, indicating high semantic overlap.
Thus, semantic meaning in AI is represented geometrically — similar meanings occupy nearby regions in vector space.
2. What is a Vector Database?
A vector database is a specialized data management system designed to store and search through these high-dimensional vector representations (embeddings).
Each data point — whether it’s a paragraph, image, or audio clip — is converted into a numerical vector using a machine learning embedding model. The database indexes these vectors and allows queries based on similarity instead of exact matching.
When a user asks a question, it’s converted into a query vector, and the database retrieves the nearest vectors — i.e., the most semantically similar results.
In other words, vector databases understand meaning, not just words.
3. Why We Need Vector Databases
Traditional databases are great for structured data and exact lookups, such as:
SELECT * FROM products WHERE name = 'Laptop';
But if you search for “best notebook for developers”, a relational database won’t know it’s semantically similar to “top laptop for programming.”
Vector databases, on the other hand, find matches by comparing vector similarity, enabling:
-
Semantic search — finding conceptually related information.
-
Context retrieval for LLMs in RAG pipelines.
-
Intelligent recommendations based on user behavior embeddings.
-
Clustering, anomaly detection, and similarity analytics in multidimensional data.
This shift from exact to semantic retrieval represents a paradigm change in AI-driven systems.
4. The Role of Embeddings
4.1 What are Embeddings?
An embedding is a fixed-length numerical representation of an input (text, image, or sound) that encodes its semantic meaning in an n-dimensional space.
For example:
| Sentence | Simplified Embedding |
|---|---|
| “AI transforms industries” | [0.21, 0.54, 0.77, …] |
| “Artificial Intelligence changes businesses” | [0.22, 0.55, 0.78, …] |
The closer the vectors, the more similar their meanings.
These embeddings are generated by pre-trained models such as:
-
OpenAI text-embedding-3-large
-
Hugging Face Sentence Transformers
-
Cohere Embed
-
Google’s Universal Sentence Encoder
4.2 Why We Must Embed Before Storage
Vector databases do not store text directly. Instead, they store the vector representations of that text.
This process is critical because:
-
Embeddings transform meaning into math.
-
Similarity searches are computed through vector distance (cosine, Euclidean, dot product).
-
Semantic context becomes retrievable across diverse formats (text, image, audio).
Without embedding, the system has no way to understand or compare meaning — it would revert to keyword-based retrieval, defeating the purpose of semantic AI.
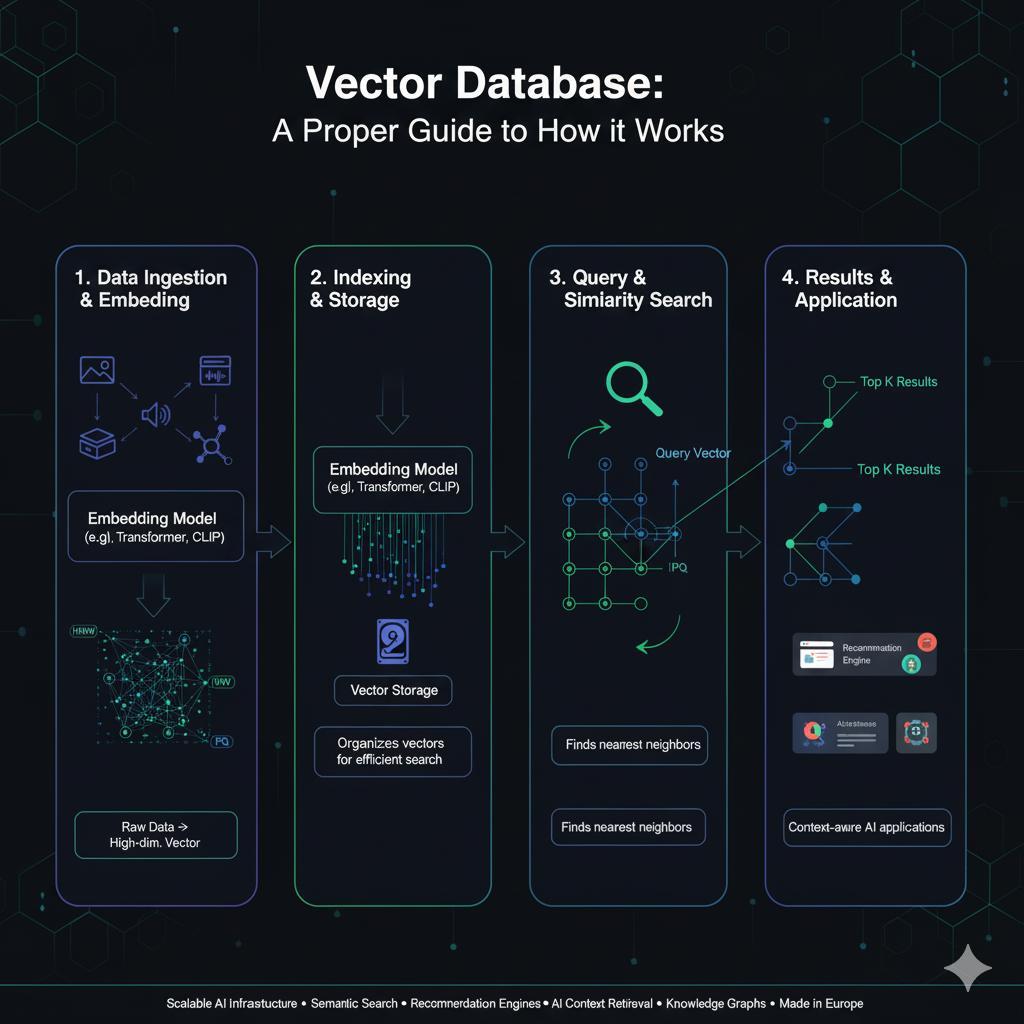
5. How Vector Databases Work
When data is ingested into a vector database, the following process occurs:
-
Embedding Generation:
Data (e.g., a paragraph, product description, or image) is converted into a vector embedding. -
Storage:
The vector, along with metadata (e.g., source, title, tags), is stored in the database. -
Indexing:
The database organizes vectors using efficient indexing algorithms (HNSW, IVF, PQ) to allow fast nearest-neighbor searches. -
Query Execution:
A query (e.g., user question) is embedded into a vector and compared to stored vectors. -
Similarity Search:
The database retrieves vectors with the smallest distance (or highest cosine similarity) to the query vector. -
Result Ranking:
The top-k most relevant results are returned to the user or AI system.
This workflow allows semantic search and retrieval at scale — powering everything from chatbots to enterprise knowledge systems.
6. Core Algorithms in Vector Databases
High-dimensional search is computationally expensive. To achieve low latency, vector databases use Approximate Nearest Neighbor (ANN) algorithms that balance accuracy with speed.
Here are the major ones:
6.1 HNSW (Hierarchical Navigable Small World)
-
Graph-based structure with multiple layers.
-
Enables logarithmic-time search for nearest neighbors.
-
Used in Qdrant, Weaviate, and Pinecone.
Advantages: High speed, dynamic insertions, excellent recall.
6.2 IVF (Inverted File Index)
-
Partitions the vector space into clusters (centroids).
-
Search is limited to relevant clusters — reducing comparisons.
-
Used in FAISS, Milvus.
Advantages: Memory efficient for very large datasets.
6.3 Product Quantization (PQ)
-
Compresses vectors into compact representations.
-
Enables billions of vectors to be stored in limited memory.
Advantages: Huge space savings; used with IVF in FAISS.
6.4 Annoy (Approximate Nearest Neighbors Oh Yeah)
-
Builds random projection trees.
-
Ideal for recommendation systems.
-
Used by Spotify for playlist similarity.
6.5 ScaNN (Scalable Nearest Neighbors)
-
Developed by Google Research.
-
Combines quantization with reordering for ultra-fast recall.
-
Optimized for TPU/GPU environments.
7. Popular Vector Databases and Ecosystem
| Database | Core Algorithm | Key Features |
|---|---|---|
| Pinecone | HNSW | Fully managed, scalable cloud-native vector DB. |
| FAISS | IVF, PQ | Open-source, GPU-accelerated for massive datasets. |
| Weaviate | HNSW | Schema-based, integrates directly with LLMs. |
| Qdrant | HNSW | Rust-based, open-source, supports hybrid queries. |
| Milvus | IVF, HNSW | Enterprise-ready, supports multimodal data. |
| ChromaDB | HNSW | Lightweight, developer-friendly, local-first for RAG. |
8. How Embeddings Are Stored
Each vector record typically includes:
-
ID – unique identifier
-
Embedding – array of floating-point numbers
-
Metadata – additional context (tags, timestamps, sources)
-
Payload – optional raw data or reference
This allows hybrid search queries like:
“Find documents about neural networks created after 2024 that are semantically similar to this text.”
9. Why Embedding First, Then Storage Is Critical
Embedding before storage ensures:
-
Semantic Understanding: Enables meaning-based retrieval.
-
Efficient Search: Reduces query complexity via precomputed vector distance.
-
Cross-Modality: Unified representation for text, images, audio.
-
Scalability: Faster indexing and parallelized retrieval.
-
Foundation for RAG: Enables LLMs to fetch relevant facts from vector memory.
This architecture is what makes systems like ChatGPT with RAG, Google Vertex AI Search, or LangChain-powered chatbots work efficiently.
10. Real-World Applications
Vector databases are used widely in:
-
RAG Chatbots – For contextual document retrieval.
-
Recommendation Engines – Suggest semantically related products or content.
-
Anomaly Detection – Identify outlier vectors in financial or sensor data.
-
Semantic Search Engines – Replace keyword-based ranking with contextual similarity.
-
Healthcare AI – Retrieve similar patient cases or molecular data.
-
Media Search – Retrieve visually or acoustically similar images/audio.
11. Conclusion
Vector databases represent a fundamental evolution in how machines process and recall knowledge. Instead of treating data as static text, they transform it into semantic representations — enabling search, reasoning, and contextual understanding at scale.
By embedding data first and then storing it in vector space, we allow AI systems to interact with knowledge the way humans do — through meaning, context, and association.
From FastAPI-integrated RAG backends to enterprise-scale retrieval systems, vector databases like Pinecone, Qdrant, and Weaviate have become essential tools for intelligent, context-aware applications.
If you’re looking to build or integrate AI-powered systems using vector databases, embeddings, or multimodal retrieval, contact us for a quote — we specialize in designing scalable, production-ready AI architectures for startups and enterprises across Europe and Belgium.